Analyzing Evals
Quick Summary
Confident AI keeps track of your evaluation histories in both development and deployment and allows you to:
- visualize evaluation results
- compare and select optimal hyperparameters (eg. prompt templates, model used, etc.) for each test run
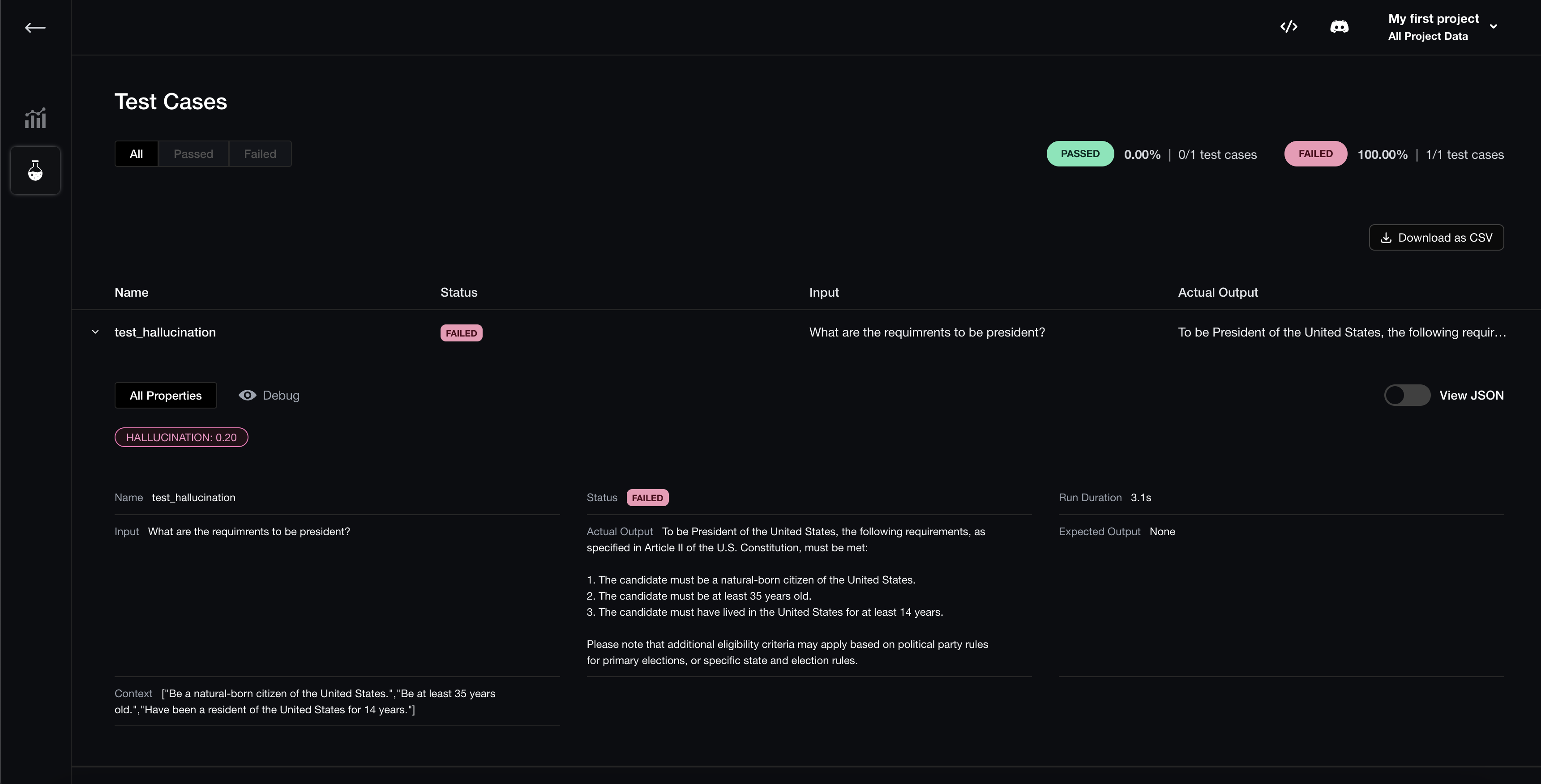
Visualize Evaluation Results
Once logged in via deepeval login, all evaluations executed using deepeval test run, evaluate(dataset, metrics), or dataset.evaluate(metrics), will automatically have their results available on Confident.
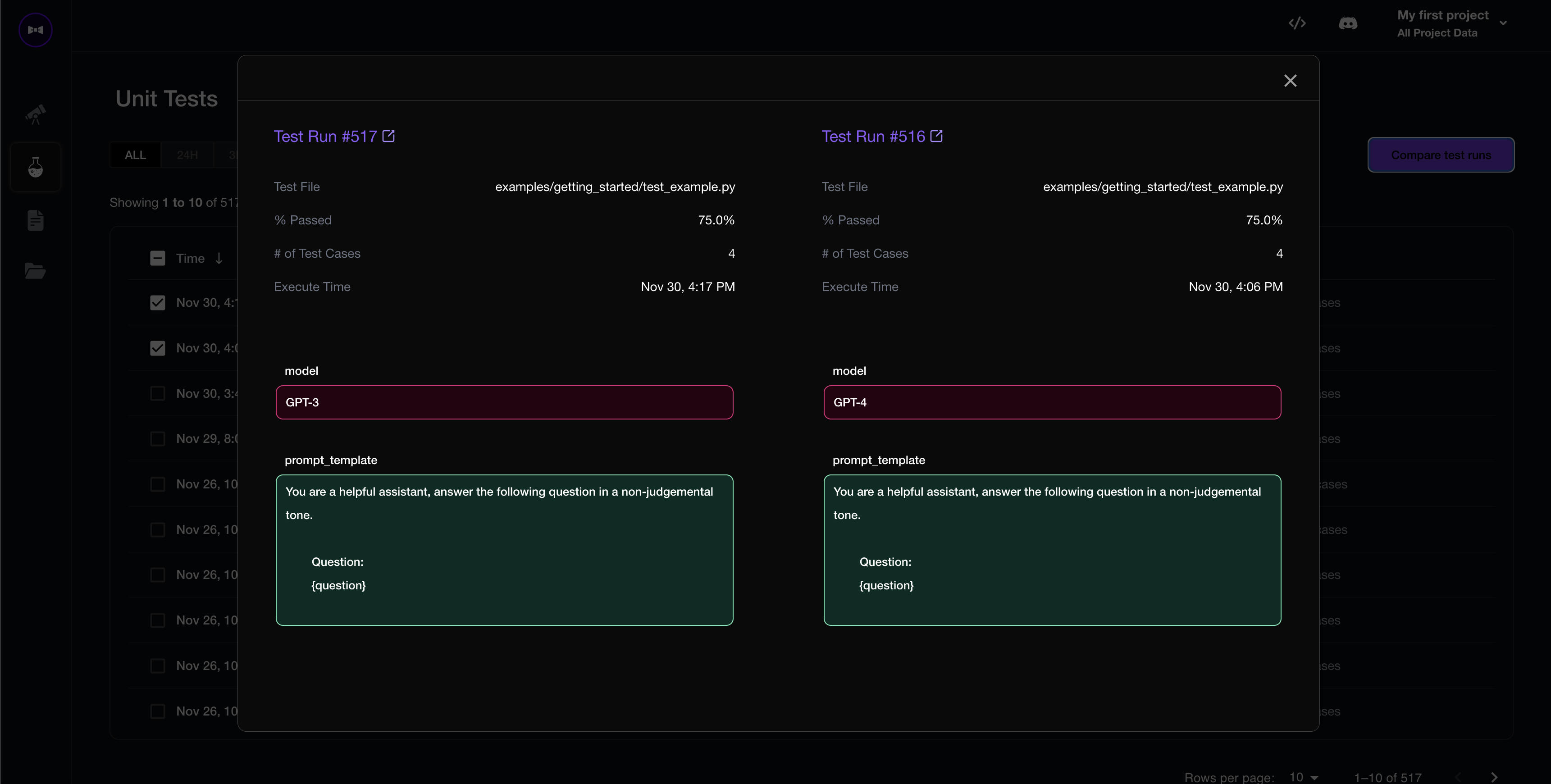
Compare Hyperparameters
Begin by associating hyperparameters with each test run:
test_example.py
import deepeval
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
def test_hallucination():
metric = HallucinationMetric()
test_case = LLMTestCase(...)
assert_test(test_case, [metric])
# Although the values in this example are hardcoded,
# you should ideally pass in variables as values to keep things dynamic
@deepeval.set_hyperparameters
def hyperparameters():
return {
"chunk_size": 500,
"temperature": 0,
"model": "GPT-4",
"prompt_template": """You are a helpful assistant, answer the following question in a non-judgemental tone.
Question:
{question}
""",
}
note
This only works if you're running evaluations using deepeval test run. If you're not already using deepeval test run for evaluations, we highly recommend you to start using it.
That's all! All test runs will now log hyperparameters for you to compare and optimize on.